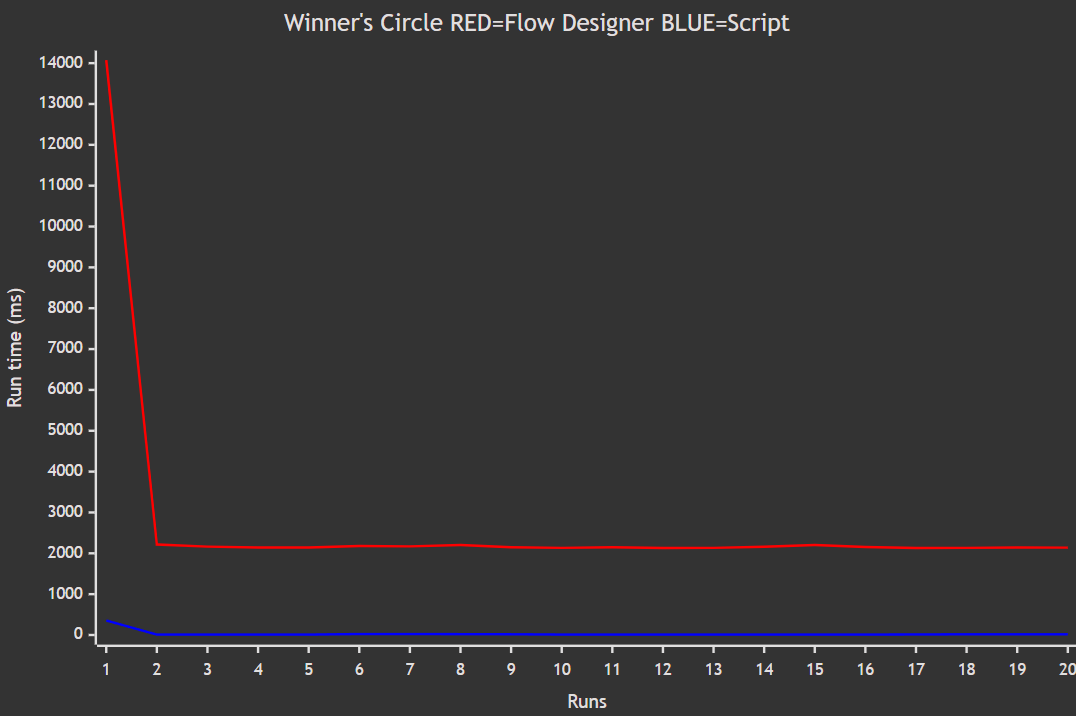
Bi-Directional Journal Entry Sync Without Infinite Loops for Comments or Work Notes
If you've ever tried to solve this problem with one or two 'after' Business Rules that simply copy comments from one record to the other… congrats, you've discovered recursion! Unfortunately, you've also discovered infinite loops. If you next tried adding .setWorkflow(false) to the Business